25. Text analysis codes for human error analysis
To utilize risk information about accidents or potential incidents for safety management purposes, it is necessary to organizeand analyze collected information.
However, although the number of railway accident reports is not large, there is a large volume of descriptive textual information due to the detailed investigations and analyses that are done for each incident.
It is therefore a laborious task to organize all the information. At the same time, the number of voluntary reports about potential incident issues has risen in many organizations over the past decade, in line with growing safety awareness and the cultivation of a stronger workplace safety climate. This trend has made the burden of organizing risk information even heavier.
In light of this, we created an analysis algorithm (code) for applying text mining technology to the descriptive data of risk information.
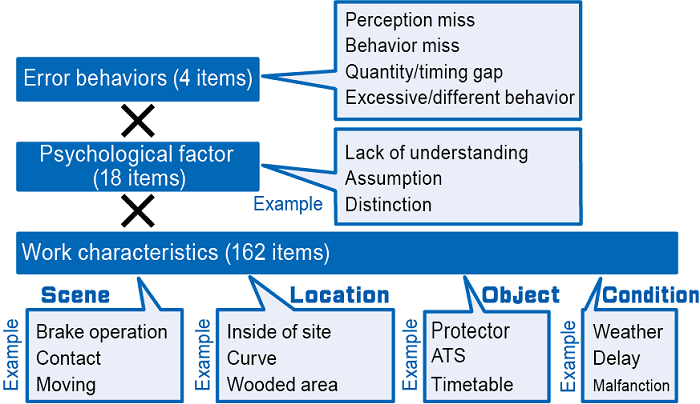
A notable feature of this algorithm is the creation of classification codes for identifying trends in the occurrence of human errors, including 162 work characteristics (scene, location, object, conditions, etc.), 18 psychological factors, and 4 error behaviors (Fig. 1).
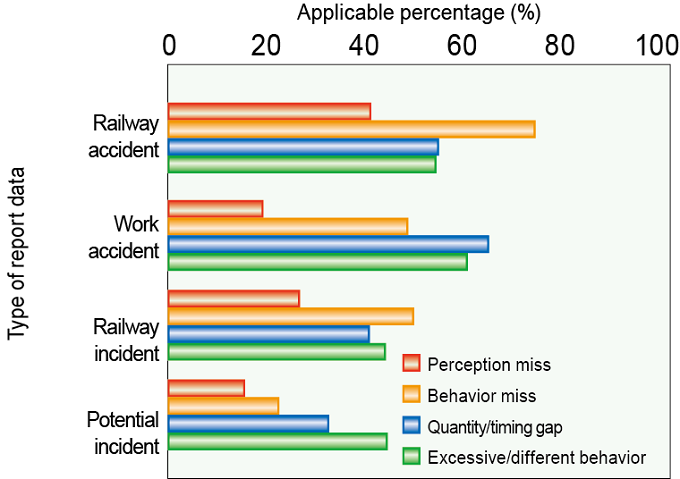
Risk information analysis based on these classification codes revealed that the quality of reported error behavior varies according to the type of risk information—for example, accident or potential incidents (Fig. 2).
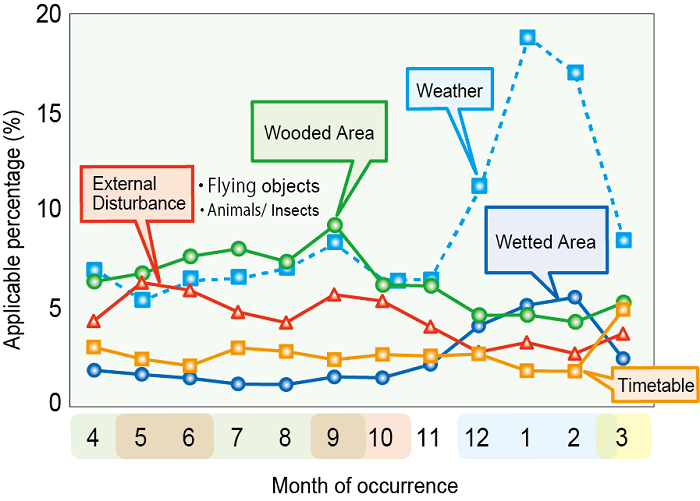
Additionally, when work characteristics were summarized by reporting month, we were able to identify the environmental factors that required attention depending on the season (Fig. 3).
This method makes it possible to analyze 95% of 4,000 items of descriptive data in just seconds, compared to the several months it would take a human to classify the same error behaviors.
We also confirmed that if the results of a human classification are assumed to be correct, the accuracy of the algorithm is in 83 to 94% (rate of matching).
Other Contents
- 22. Earthquake early detection method based on deep learning of seismic motion
- 23. HILS for the current collection systems using a High-Speed Test Facility for Pantograph/OCL Systems
- 24. Mechanism of increasing wear rate of contact wires near pantograph stopping positions of Shinkansen
- 25. Text analysis codes for human error analysis
- 26. Method of visualizing sound wave propagation for clarification and prediction of railway noise
- 22. Earthquake early detection method based on deep learning of seismic motion
- 23. HILS for the current collection systems using a High-Speed Test Facility for Pantograph/OCL Systems
- 24. Mechanism of increasing wear rate of contact wires near pantograph stopping positions of Shinkansen
- 25. Text analysis codes for human error analysis
- 26. Method of visualizing sound wave propagation for clarification and prediction of railway noise